I have a replication volume as bellows:
address@hidden disk]# gluster volume info rep
Volume Name: rep
Type: Replicate
Volume ID: 0f7eb8a0-92d7-4911-b766-f23ed870cf3d
Status: Started
Number of Bricks: 1 x 2 = 2
Transport-type: tcp
Bricks:
Brick1: gluster001:/disk/sdc
Brick2: gluster002:/disk/sdb
The sdc and sdb are both raid5 device in 3 SAS disks.
And I have 3 clients (gluster-client001,gluster-client002,gluster-client003) mount on the same replication volume.To test the self-heal function, I clean gluster001:/disk/sdc (rm –rf /disk/sdc/*), and run “gluster volume heal rep full”. I use the iftop to check the process and I get the log :
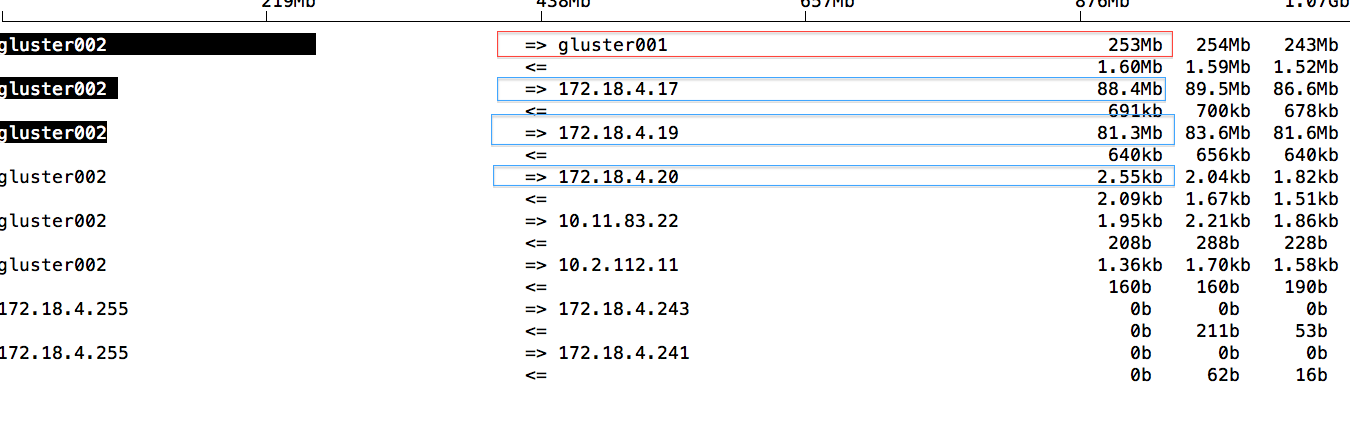 The clients are 172.18.4.17, 172.18.4.19 and 172.18.4.20. There are no jobs running on the clients. But from the log, the client 4.17 and 4.19 are reading something from the gluster002 server. And the self-heal process’s performance seems to be affected, only 253Mb/s.
The clients are 172.18.4.17, 172.18.4.19 and 172.18.4.20. There are no jobs running on the clients. But from the log, the client 4.17 and 4.19 are reading something from the gluster002 server. And the self-heal process’s performance seems to be affected, only 253Mb/s.
My Questions, thanks:
@1: why/what are the clients 4.17 and 4.19 reading from gluster002?
@2: how to accelerate the self-heal?