Description: Text document
|
| From: | Peter Bex |
| Subject: | [Chicken-hackers] [PATCH] Get rid of expensive APPEND calls in prepare-for-code-generation |
| Date: | Fri, 3 Feb 2012 20:30:58 +0100 |
| User-agent: | Mutt/1.4.2.3i |
Hi all,
Here's some more low-hanging fruit that I found; the preparation step
has a bad case of exponential complexity (it's even marked
"XXX could (should) be optimized")
Fixing this (see patch 0001) shaved off another one and a half *minute*
of compilation time for the numbers tests. The fix is simply to assign
literal indexes in reverse, and keep a counter to avoid having to call
LENGTH and APPEND all the time. The index of a literal is simply its
position, but since it's calculated from the end instead of the
beginning we need to subtract it from the total length of the list to
compensate.
I've also simplified the code a little bit by removing the branch for
flonums and collapsing it into one for all types (except lambda info),
by introducing a new procedure "posv", which is to posq as memv is to
memq. eqv? should only return true when both numbers share (in)exactness
and have the same value, and it works for other types of non-immediate
literals just as well (list literals, vector literals etc) as posq does.
This should also be faster than SRFI-1's general-purpose LIST-INDEX.
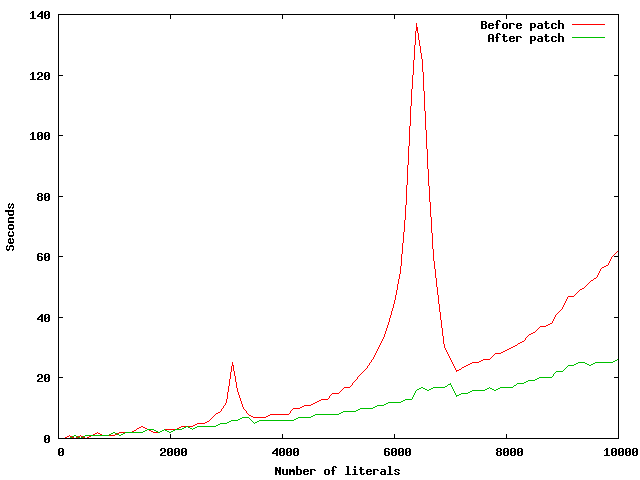
The graphs I created while working on this patch are totally weird.
The current HEAD code ("before patch", the red line) starts out like
a typical exponential curve but then after about 6000 literals it
drops off sharply and it continues in a much shallower curve.
I haven't been able to determine what causes this. Perhaps some GC
adjustment after something reaches a limit?
The green "after patch" line is more linear (at least on the first 7000
expressions, didn't try more).
The other patch (0002) I don't care about as much but it seemed like
a sane thing to do; it basically applies the same idea to the
environment that's carried by the WALK procedures. However, I tried
quite a few programs but wasn't able to trigger any exponential behavior
in this. Maybe my programs were too simple and couldn't fool the
optimizer which removed all the LETs or something?
Anyway, theoretically this should have the same effect, but on the
numbers tests it didn't have any measurable effect.
It does complicate the code a bit more, so if it's decided that it's
not worth it, we can put it on ice until we need it in a real-world
situation. The first patch is a big improvement though!
PS: I got *really* thrown off by the fact that the IMMEDIATE? predicate
from support.scm doesn't really check for immediate values, but actually
checks for values that can be encoded as immediate literals. Took me
a while before I understood the cause of a segfault in the numbers test.
Maybe this procedure can be renamed to ENCODE-AS-IMMEDIATE? or C-IMMEDIATE?
or something else that's slightly more descriptive? Suggestions are
welcome.
Cheers,
Peter
--
http://sjamaan.ath.cx
--
"The process of preparing programs for a digital computer
is especially attractive, not only because it can be economically
and scientifically rewarding, but also because it can be an aesthetic
experience much like composing poetry or music."
-- Donald Knuth
![]() 0001-When-preparing-for-compilations-don-t-keep-re-append.patch
0001-When-preparing-for-compilations-don-t-keep-re-append.patch
Description: Text document
![]() 0002-Similar-to-1b6c8f6797ec4a142074c7408aada9d44d2e1674-.patch
0002-Similar-to-1b6c8f6797ec4a142074c7408aada9d44d2e1674-.patch
Description: Text document
![]() comparison.png
comparison.png
Description: PNG image
| [Prev in Thread] | Current Thread | [Next in Thread] |
{kind=link}